Michał Chromiak's blog
Michał Chromiak's blog Decision Transformer: Unifying sequence modelling and model-free, offline RL
"Decision Transformer: Reinforcement Learning via Sequence Modeling" - Research Paper Explained
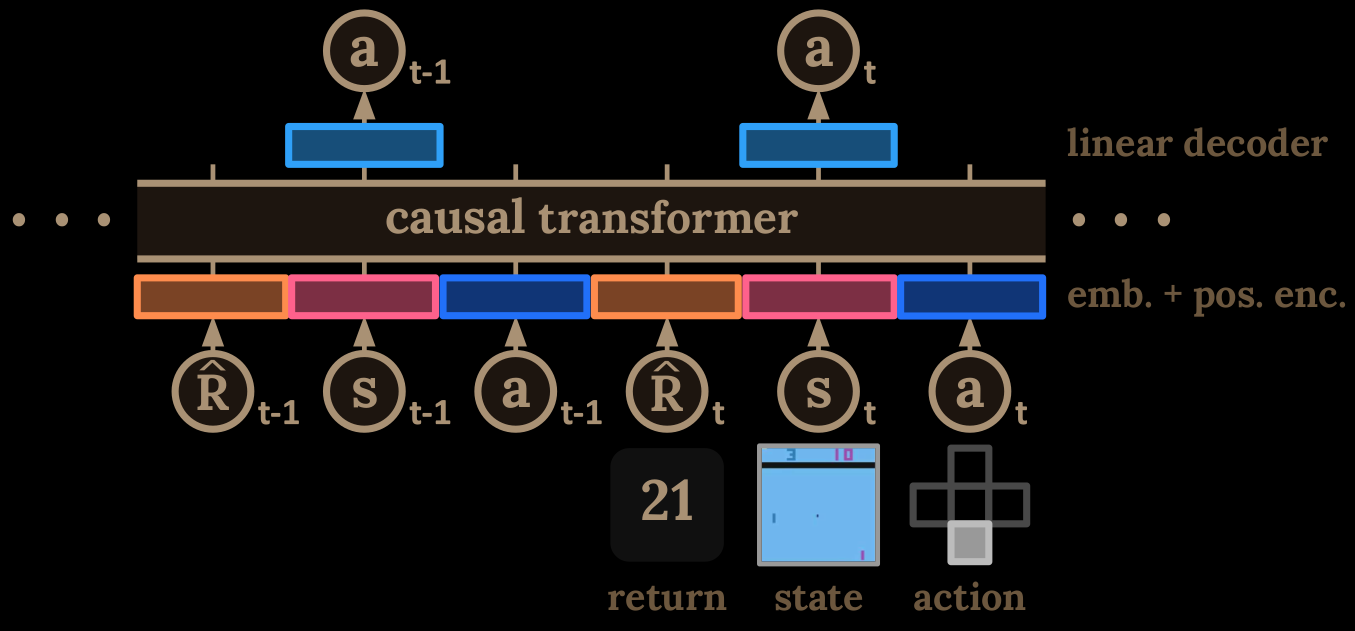
Can we apply massive advancements of Transformer approach with its simplicity and scalability to Reinforcement Learning (RL)? Yes, but for that - one needs to approach RL as a sequence modeling problem. The Decision Transformer does that by abstracting RL as a conditional sequence modeling and using language modeling technique of casual masking of self-attention from GPT/BERT, enabling autoregressive generation of trajectories from the previous tokens in a sequence. The classical RL approach of fitting the value functions, or computing policy gradients (needs live correction; online), has been ditched in favor of masked Transformer yielding optimal actions. The Decision Transformer can match or outperform strong algorithms designed explicitly for offline RL with minimal modifications from standard language modeling architectures.
more ...