 Michał Chromiak's blog
Michał Chromiak's blog DINO: Improving supervised ViT with richer learning signal from self-supervision
"Emerging Properties in Self-Supervised Vision Transformers" - Research Paper Explained
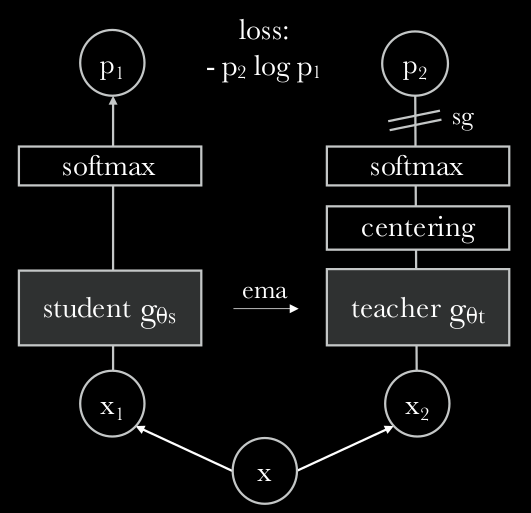
Self-DIstillation with NO labels (DINO) is a self-supervised method based on Vision Transformer (ViT) from Facebook AI with the ability to learn representation from unlabeled data. The architecture is able to learn automatically class-specific features, allowing the unsupervised object segmentation. The paper claims that the self-supervised methods adapted to ViT not only works very well, but one can also observe that the self-supervised ViT features contain explicit semantic segmentation information of an image, which is not that clear in case of supervised ViT, nor with convnets. The benefit of such observation is that such features are also very good k-NN classifiers. The performance results are reported to be highly dependent on two SSL approaches: the momentum teacher and multicrop training. In this blog post we will explain the details on what DINO is all about.
more ...