 Michał Chromiak's blog
Michał Chromiak's blog Masked autoencoder (MAE) for visual representation learning. Form the author of ResNet.
"Masked Autoencoders Are Scalable Vision Learners" - Research Paper Explained
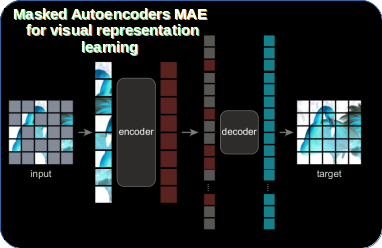
MAE is a simple autoencoding approach that reconstructs the original signal - image - given its partial observation. Thanks to successful introduction of patching approach in ViT it has become more feasible for CV as an alternative to convnets. The MEA paper use the ViT's patch-based approach to replicate masking strategy (similarly to BERT) for image patches. MAE randomly samples (without replacement) uniformly distributed and non-overlapping patches regularly created from image. MAE learns very high-capacity models that generalize well. Thanks to very high masking ratio (e.g., 75%) authors were able to reduce the training time by >3x while at the same time reducing the memory consumption thus, enabling the MAE to scale better for large models, like ViT-Large/-Huge on ImageNet-1K with 87.8% accuracy.