 Michał Chromiak's blog
Michał Chromiak's blog This article is currently actively developed. Please stay tuned for the UPDATES on details of the DINOv2 paper. Thanks!
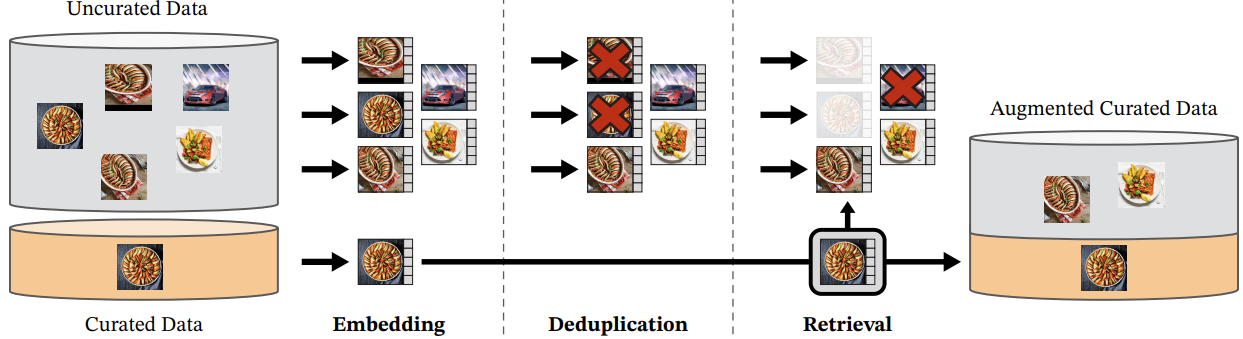 Figure 1. DINO v2 - overview of data processing pipeline.
Figure 1. DINO v2 - overview of data processing pipeline.
"DINOv2: Learning Robust Visual Features without Supervision" - paper explained.🔗
In this article we will explain and discuss the paper on simple, effective, and scalable modification of DINO and iBOT.
"DINOv2: Learning Robust Visual Features without Supervision": ArXiv Apr, 18, 2023
DINOv2 is a series of image encoders pretrained on large curated data with no supervision. DINOv2 are pretrained visual models, trained with different Vision Transformers (ViT) (Dosovitskiy et al., 2020).
This paper represents the first use of SSL (self-supervised learning) techniques (MAE, DINO , SEERv2, MSN, EsViT, Mugs and iBOT ) on image data, resulting in visual features that exhibit similar, or even surpass the performance of weakly supervised (learning) approaches (CLIP, OpenCLIP, SWAG) across a wide range of benchmarks / tasks. Moreover, these features can be obtained without the need for finetuning. The models developed in this study exhibit a few noteworthy properties, such as an understanding of object parts and scene geometry regardless of the image domains.
Figure 2. DINO v1 Vs v2 comparison of segmentation precision. (Source).
TL;DR🔗
- DINOv2 family of models drastically improves over the previous state of the art in self-supervised learning (SSL), and reaches performance comparable with weakly-supervised features (WSL).
- DINOv2 delivers strong performance and does not require fine-tuning.
-
DINOv2 enables learning rich and robust visual features without supervision which are useful for both image-level visual tasks and pixel-level tasks. Tasks supported include image classification, instance retrieval, video understanding, depth estimation.
-
Self-Supervised Learning enables DINOv2 to be used to create general, multipurpose backbones for many types of computer vision tasks and applications. The model generalizes well across domains without fine-tuning.
-
Authors composed of a large-scale, highly-curated, and diverse pertaining dataset to train the models. The dataset includes 142 million images.
-
Efforts dealing with the instability that arises from training larger models, including more efficient implementations that reduce things like memory usage and hardware requirements.
-
DINOv2 pretrained models are released as:
- Pretraining code and recipe for Vision Transformer (ViT) models,
- Checkpoints for ViT models available via PyTorch Hub.
-
Learn features directly from images without relying on text descriptions, which can lead to a better understanding of local information and can learn from any collection of images.
-
The pretrained version of DINOv2 is already available and competes with CLIP and OpenCLIP on a wide array of tasks.
Contribution of paper:🔗
- Reiterate on existing discriminative SSL solutions combining feature learning on image and patch level (see iBOT, Zhou et al., 2021) from the perspective of larger dataset.
-
Learned patch embeddings:
- Model learnt to parse parts of objects even without being trained to do so.
- Components with same semantics (wing, head, ) are shared among objects of different classes. See below Figure
-
Larger model & data sizes made authors to improve stability and acceleration of discriminative SSL methods resulting in 2x faster and with 3x less memory thus enabling 1) longer training and 2) larger batch sizes. Used techniques:
- Fast and memory-efficient attention - improve compute efficiency - FlashAttention, Dao et al. 2022
- Nested tensors in self-attention from Modular XFormers lib from MetaAI, 2022
- Efficient stochastic depth - improve in compute efficiency and memory - modified (Huang et al., 2016) by skipping (instead of masking) computation of the dropped residuals
- Fully-Sharded Data Parallel (FSDP)- memory saving - split the model replicas across GPUs (more memory from more GPUs)
- use of PyTorch FSDP $\rightarrow$ broadcasting weights and reducing gradients is done in
float16precision for the backbone (insteadfloat32) - MLP heads gradients are reduced in
float32to avoid training instabilities
- use of PyTorch FSDP $\rightarrow$ broadcasting weights and reducing gradients is done in
- Model distillation (Hinton et al., 2015)
- used for smaller models that are distilled from largest ViT-g
- apply the iBOT loss on the two global crops
-
Automatic pipeline design that filter & rebalance the dataset from collection of unstructured (no need for image metadata) images based only on:
- data similarity
- no manual annotation required
- Provide collection of pretrained (with different ViT) visual models (DINOv2), trained on pipelined data.
- Show that with SSL learning transferable frozen features improves SSL SOTA by a very large margin and is competitive with best weaikly-supervised models.
 Figure 1. Patch embeddings visualized with PCA.
Figure 1. Patch embeddings visualized with PCA.Motivation🔗
The requirement for human annotations of images poses a constraint, limiting the quantity of data available for model training. However, self-supervised training using DINOv2 offers a promising solution, particularly for specialized application domains such as cellular imaging, by facilitating the creation of foundational models. Moreover, DINOv2's self-supervised learning approach aims at overcoming the constraints associated with text descriptions, rendering it a potent tool for computer vision. Additionally, the absence of the need for fine-tuning ensures that the backbone remains general, allowing for the simultaneous use of the same features across multiple tasks.
Intro🔗
DINOv2 represents an advanced approach to training computer vision models using self-supervised learning. This method enables the model to learn from a diverse range of image collections without necessitating labels or metadata. In contrast to conventional image-text pretraining techniques that rely on captions to comprehend image content, DINOv2's reliance on self-supervised learning obviates the need for textual descriptions. DINOv2 acquires the capability to anticipate the relationship between distinct elements of an image, which aids in comprehending and representing its underlying structure. As a result, the model can assimilate more detailed information regarding images, including spatial relationships and depth estimation.
Applications: classes of problem is the algorithm well suited🔗
DINOv2's robust predictive abilities render it well-suited for various computer vision applications, including classification, segmentation, and image retrieval. Notably, the features produced by DINOv2 outperform specialized state-of-the-art pipelines for depth estimation, both in-domain and out-of-domain. With its adaptability, DINOv2 can serve as a multipurpose backbone for diverse computer vision tasks, which can lead to the creation of foundational cell imagery models and subsequent biological discoveries.
- Instance Retrieval

Directly use frozen features to find art pieces similar to a given image from a large art collection. DINOv2 frozen features can readily be used to retrieve images similar to a query image using a non-parametric approach: database images are simply ranked according to the similarity of their features with those of the query image.
- Semantic Segmentation
 DINOv2 frozen features can readily be used in models predicting per-pixel object class in a single image. Competitive results without any fine-tuning on clustering an images into object classes.
DINOv2 frozen features can readily be used in models predicting per-pixel object class in a single image. Competitive results without any fine-tuning on clustering an images into object classes.
- Depth Estimation
 DINOv2 frozen features can readily be used in models predicting per-pixel depth from a single image, both in and out-of-distribution.
State-of-the-art results and strong generalization on estimating depth from a single image.
DINOv2 frozen features can readily be used in models predicting per-pixel depth from a single image, both in and out-of-distribution.
State-of-the-art results and strong generalization on estimating depth from a single image.
Conclusions:🔗
Several obstacles were surmounted during the course of this study, including the development of a substantial and refined training dataset, optimization of the training algorithm and its implementation, and the design of an effective distillation pipeline.
DINOv2 is capable of producing high-performance features that can serve as inputs for straightforward linear classifiers. This adaptability allows DINOv2 to function as a versatile backbone for numerous computer vision applications. Experiments indicates that the features produced by DINOv2 exhibit strong predictive capabilities on various tasks, including classification, segmentation, and image retrieval. Additionally, the findings demonstrate that DINOv2's features outperform specialized state-of-the-art pipelines for depth estimation, both in-domain and out-of-domain. This robust out-of-domain performance is attributed to the synergistic combination of self-supervised feature learning and the utilization of lightweight task-specific modules, such as linear classifiers. Lastly, the backbone remains general, as it avoids fine-tuning, and the same features can be employed simultaneously across various tasks.
Future research:🔗
-
It is expected that understanding of object parts and scene geometry regardless of the image domains are just the initial set of properties that will grow with model scale and data similarly to instruction emergence in large language models [Wei J. et al. 2022].
-
The paper shows that visual features are compatible with classifiers as simple as linear layers - meaning the underlying information is readily available. This ability can be leverage to train a a language-enabled AI system that can process visual features as if they were word tokens, and extract the required information to ground the system.
Useful resources for learning more about the algorithm:🔗
-
Demos:
- "DINOv2: State-of-the-art computer vision models with self-supervised learning- April 17, 2023 MetaAI blog post on general DINOv2 idea and results
- PapersWithCode
Comments
comments powered by Disqus