 Michał Chromiak's blog
Michał Chromiak's blog Transformer based models has become the dominant part of modern SOTA research for NLP. ERNIE 2.0 is no different. Lets deep dive into what novel is about the second version of Ernie.
TL:DR🔗
Focus attention to more than just co-occurence. Contribution of paper:
- Design of continual pre-training framework ERNIE 2.0, which supports customized training tasks and multi-task pre-training in an incremental way.
- ERNIE 2.0 achieves significant improvements over BERT and XLNet on 16 tasks including English GLUE benchmarks and several Chinese tasks.
Intro🔗
Co-occurence of words and sentences is the main workhorse of current NLP SOTA solutions. ERNIE 2.0 tries to get a bigger picture with its continuous pre-training.
Motivation🔗
It is the fact that with current solutions, training of the model usually focus on couple of tasks to get the notion of co-occurrence of words and sentences. Those pre-training procedures involved word-level and sentence-level prediction or inference tasks. The closest competitors like Google's BERT captured co-occurrence information by combining a masked language model and a next-sentence prediction task. On the other hand, this co-occurrence information is captured by XLNet by constructing a permutation language model task.
With Ernie 2.0 however, the vision becomes broader than just co-occurence. This includes more lexical, syntactic and semantic information from training corpora in form of named entities (like person names, location names, and organization names), semantic closeness (proximity of sentences), sentence order or discourse relations. This is done with Ernie 2.0: continual pre-training framework, by building and learning incrementally pre-training tasks through constant multi-task learning.
The important aspect is that at any time a new custom task can be introduced, while sharing the same encoding network. Thanks to this, a significant amount of information can be shared across different tasks. Ernie 2.0 framework is continuously pre-training and updating the model and gaining enhancements in information through multi-task learning, hence more holistically understand lexical, syntactic and semantic representations.
- Paper: Ernie 2.0: A continual pre-training framework for language understanding. ArXiv.
- Code for fine-tuning and pre-trained models for English: GitHub
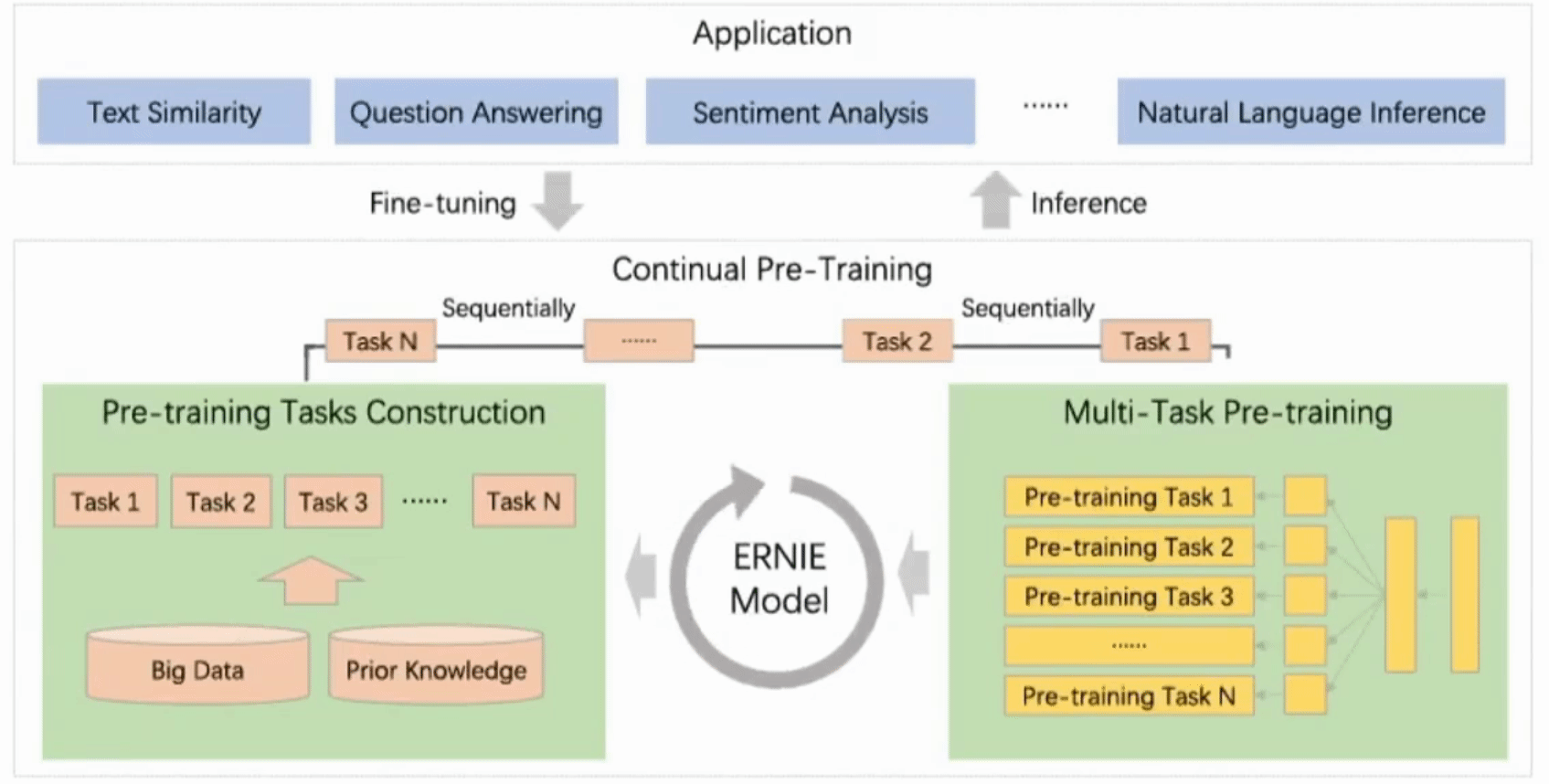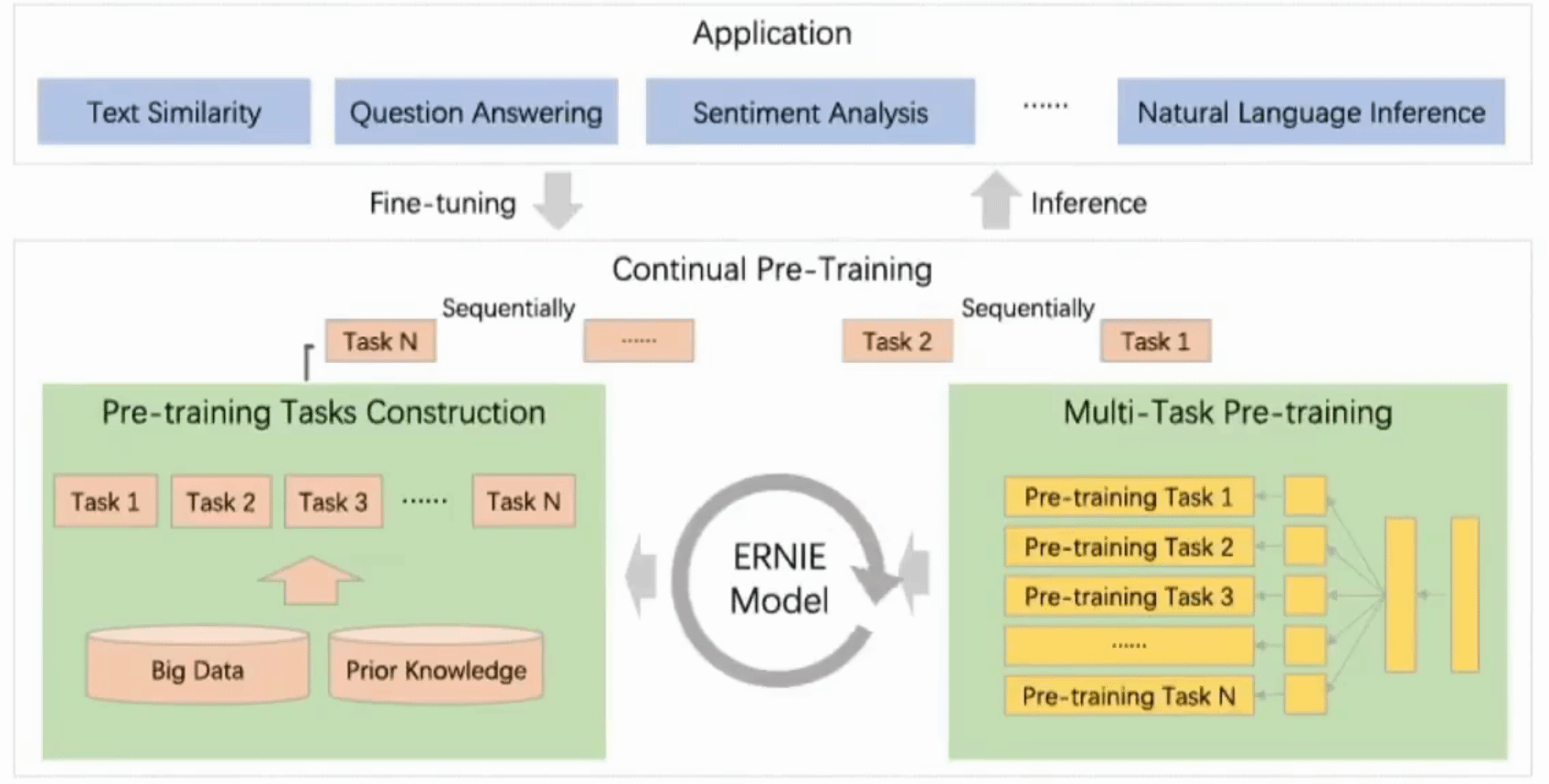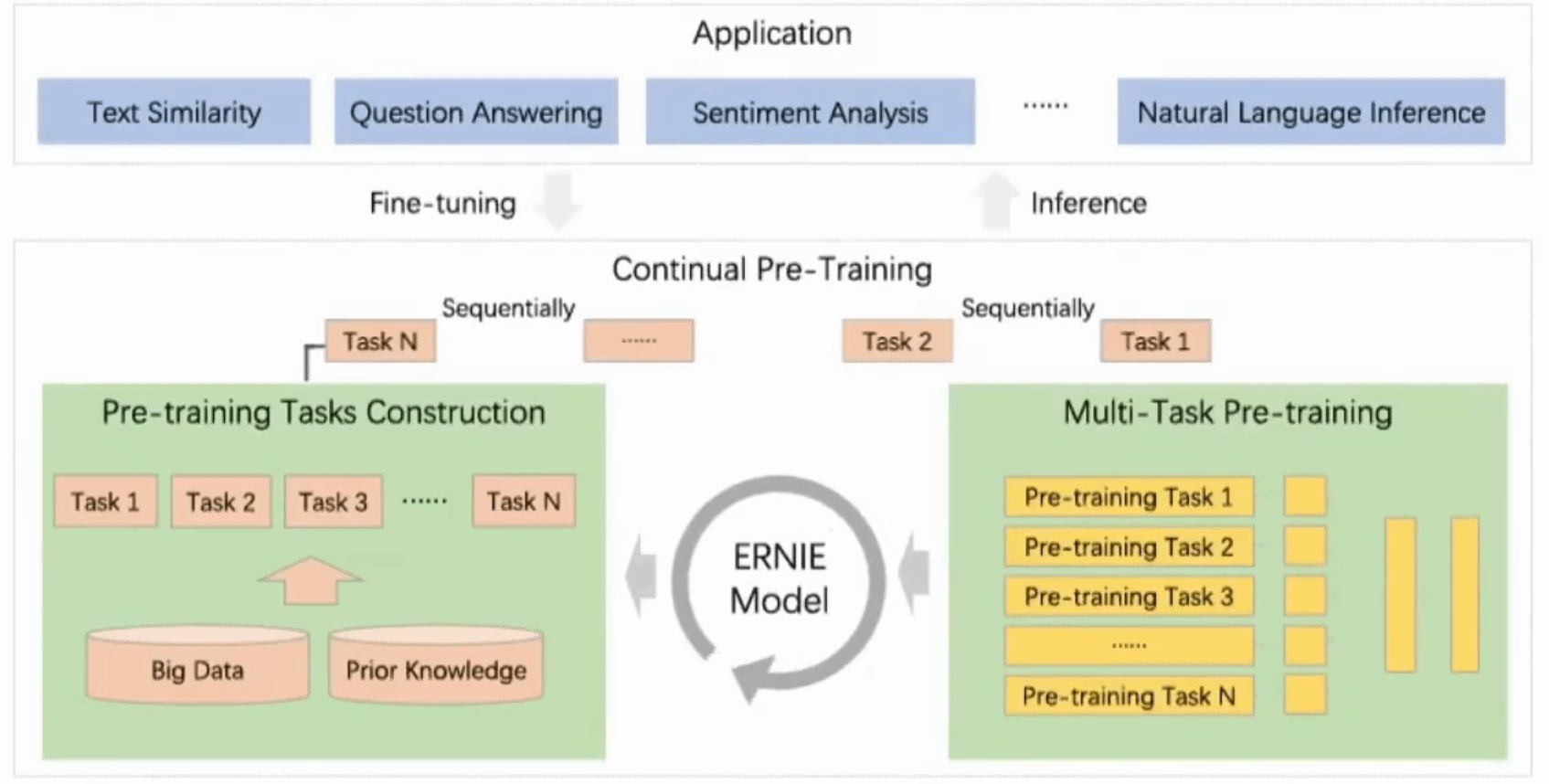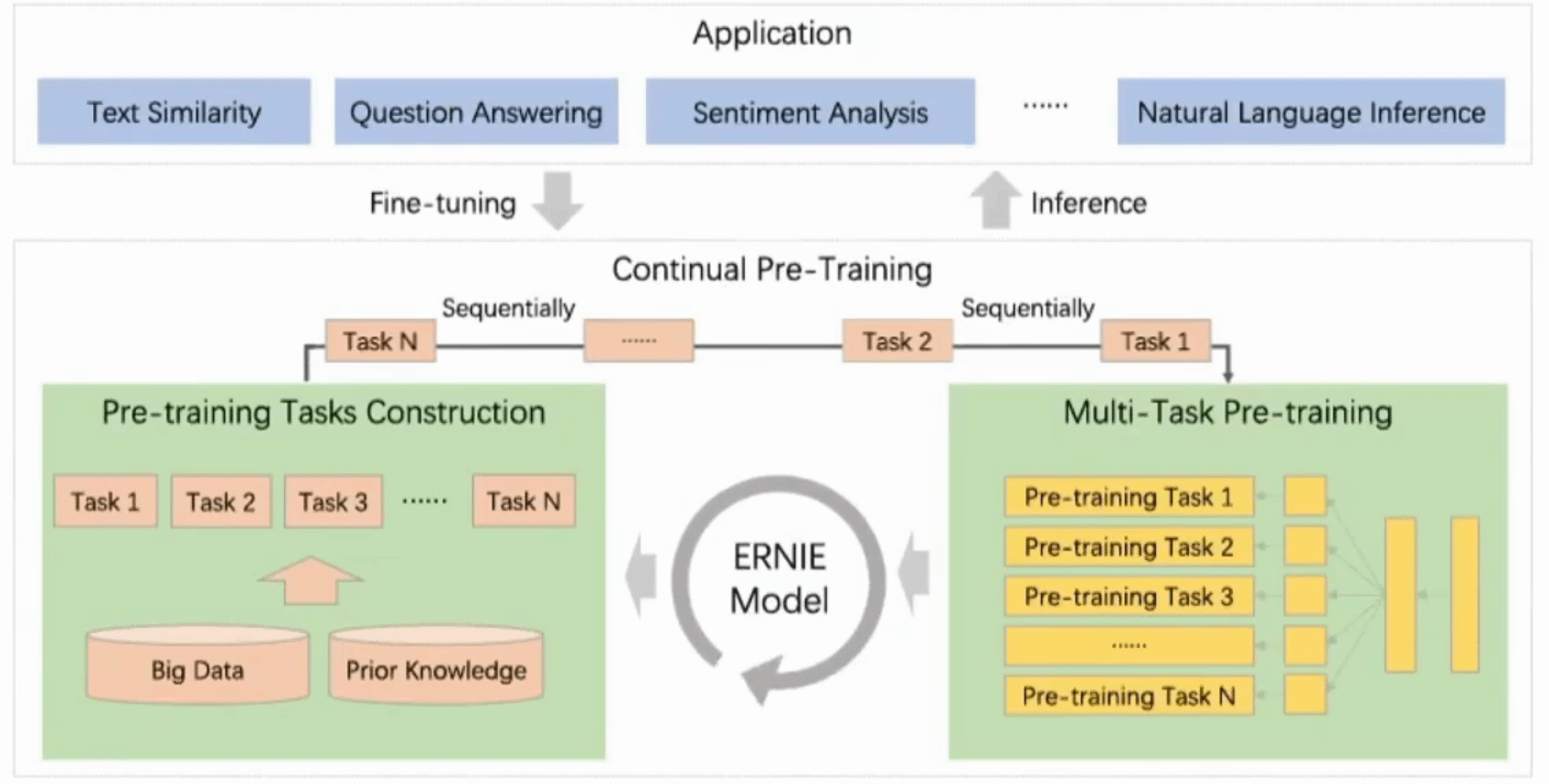
Figure 1. A continual pre-training framework for language understanding.
The continual pre-training🔗
The continual pre-training consists of two phases:
1. Continuously construct unsupervised pre-training tasks using the big data and with prior knowledge involved
This phase include three types of tasks:
- word-aware tasks: Knowledge Masking, Capitalization Prediction, Token-Document Relation Prediction
- structure-aware tasks: Sentence Reordering, Sentence Distance
- semantic-aware tasks: Discourse Relation, IR Relevance
For the details of the tasks please refer to the paper. All tasks are based on self/weak-supervised signals without human annotation.
2. Incrementally update the ERNIE model via multi-task learning Continuously, task-by-task new tasks are added starting from first, initial task to train initial model. Then next task's parameters are initialized to the values already learned form the previous one. This way the parameters' "knowledge" is passed on and accumulated within the consecutive tasks.
This goal is achieved with series of shared text encoding layers that encodes the contextual information possibly customized with RNNs or deep Transformer. The parameters of the encoder are the ones that are updated when a new task is introduced.
There are two types of loss functions: sequence-level and token-level. For each task sentence-level loss functions can be combined with token-level loss functions creating the task's loss function used to update the model.
Fine tuning for tasks🔗
The phase of fine-tuning of the pre-trained model for language understanding tasks (e.g question answering, natural language inference, semantic similarity) is done with task specific supervised data.
ERNIE 2.0 model🔗
The model is similar to BERT or XLNet.
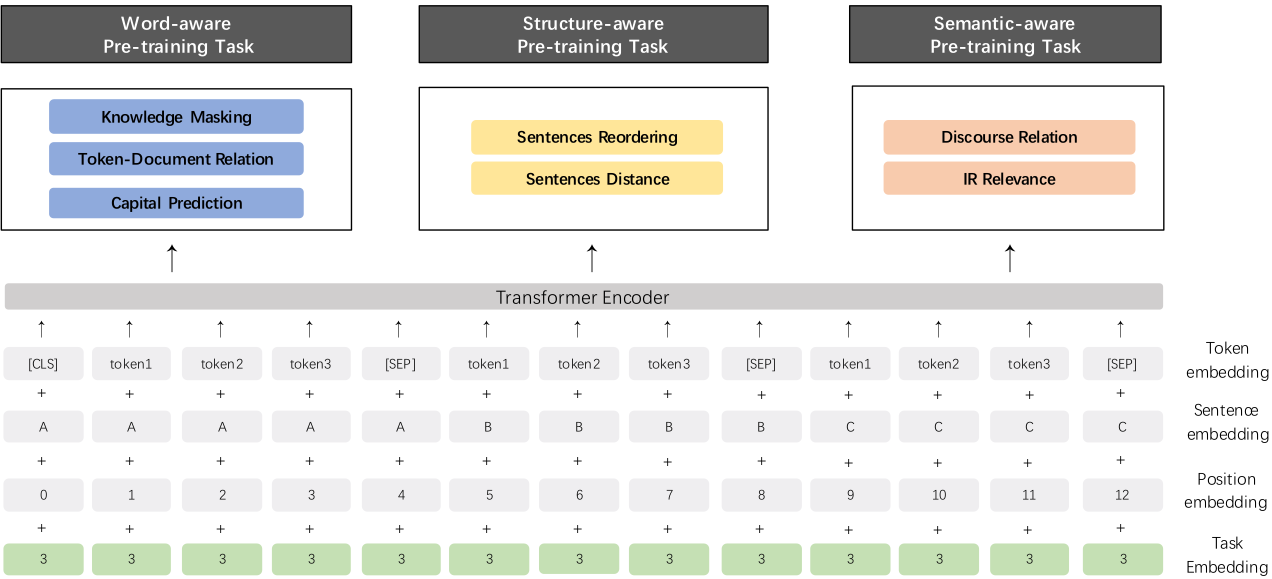
Figure 2. ERNIE 2.0 model structure. The input embedding consists of the token embedding, the sentence embedding, the position embedding and the task embedding. There are seven pre-training tasks in the ERNIE 2.0 model.
Encoder🔗
Is a multi-layer Transformer same as in BERT, GPT, XLM. Transformer generate sequence of contextual embeddings for each token. Additional markers are added to the start of the sequence and separator symbol is added to separate intervals for the multiple input segment tasks.
Task embeddings🔗
The model feeds task embedding to modulate the characteristic of different tasks.Each task has an id ranging from 0 to N. Each task id is assigned to one unique task embedding. The model input contains the corresponding token, segment, position and task embedding. Any task id can initialize model in the fine-tuning process.
Results🔗
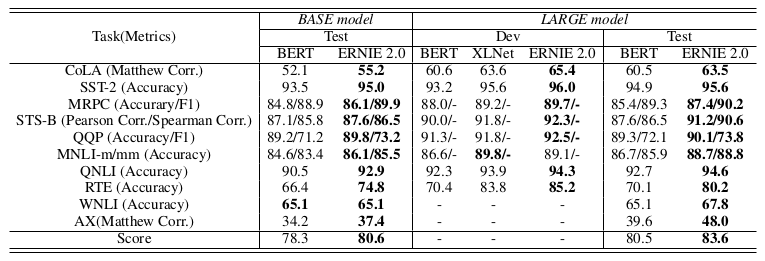
Figure 3. ERNIE 2.0 The results on GLUE benchmark for English tasks.
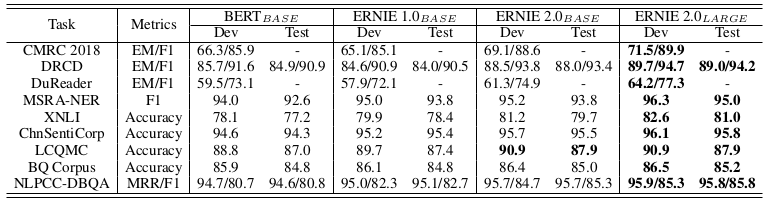
Figure 4. ERNIE 2.0 The results of 9 common Chinese NLP tasks.
Comments
comments powered by Disqus