 Michał Chromiak's blog
Michał Chromiak's blog  Figure 1. MAE test results for COCO validation images reconstruction. Masked | Reconstruction | Ground-truth
Figure 1. MAE test results for COCO validation images reconstruction. Masked | Reconstruction | Ground-truth
The MAE for scalable learning paper explained.🔗
In this article we will explain and discuss the paper on simple, effective, and scalable form of a masked autoencoder (MAE) for visual representation learning:
"Masked Autoencoders Are Scalable Vision Learners": ArXiv Nov, 11, 2021
TL;DR🔗
- MAE is asymmetric (decoder use <10% computation per token of encoder) encoder-decoder architecture with only the NON-masked, visible patches / tokens (25% of all patches) as the encoder input, and encoded visual patches (encoder output) and masked tokens as the decoder input - resulting in decreased memory and computation requirements.
- Small decoder (default decoder has <10% computation per token vs. the encoder) reconstruct the original image pixels (by predicting the pixel values for each masked patch) only for training.
- After training decoder is discarded (decoder), while the encoder is applied to unmasked images to produce representations for recognition tasks.
- The mean squared error (MSE) loss function is computed between the reconstructed and original images in the pixel space.
- Removing masked patches from encoder improve performance by 14%.
- MAE outperforms DINO, MoCO, BEiT on on ImageNet-1K.
- MAE can scale up easily: by fine-tuning 448 size, achieve 87.8% accuracy, using only ImageNet-1K data.
- MAE is considerably faster (3.5× per epoch) than BEiT.
Contribution of paper:🔗
- Using pixels as reconstruction target instead of fancier things works very well. Per-patch normalization helps quite a bit.
- Asymmetric autoencoder helps to improve performance.
- In contrast to recent contrastive learning solutions it does not require augmentation heavily (center-crop, no flipping).
Motivation🔗
The masking idea has been very successful in NLP, especially since BERT. In CV, applying masking in form of mask tokens, or positional embeddings was challenging due to specifics of CNN-based architectures. With ViT eliminating CNN limitations this has become possible. With contrast to NLP, images contain a sparse semantic information that have potential to optimize image representation by applying a technique to reduce the heavy spacial redundancy, that consumes processing power, but on the other hand - can be reconstructed with high level understanding of objects and scenes. Paper focus here around the idea of masking high portions of image just to create a self-supervised task to reconstruct it.
This decoder-based reconstruction becomes even more important for images if we decide to use low-level pixel wise reconstruction that has minimal semantic level without perception of object, scene no parts of bigger entities.
Objective, or goal for the algorithm🔗
Objective of the algorithm is to prepare universal latent representation for downstream (transfer-learning) tasks. The goal of this paper is to adapt a well known pre-training techniques based on autoencoders and masking, while apply them for ViT based approach for computer vision tasks.
Intro🔗
The introduction ResNet has been very impactful in deep learning, especially in computer Vision (CV), and has also been heavily utilized in recent advances in self-supervision such as BYOL, MoCo or SimCLR1.
Patch-based self-supervision has been a topic for a while now, but mostly it was tied to ResNets with all their complexity included. With ViT this has been greatly simplified.
With use of ViT first interesting approach for patch-based SSL has been proposed in BEiT: BERT Pre-Training of Image Transformers (Jan, 2021), using masked approach for images based on image patches and image discrete visual tokens. BEiT's pre-training objective was to recover original visual tokens based on the masked image patches. Now the masked autoencoder approach has been proposed as a further evolutionary step that instead on visual tokens focus on pixel level. MAE outperforms BEiT in object detection and segmentation tasks. Paper also claims that MAE does not need (for normalized pixels) tokenization (e.g. dVAE) to be on pair or better in terms of performance thus, being faster and simpler.
The processing strategy of the algorithm🔗
MAE is based on autoencoder architecture with encoder that creates the latent representation from observed signal and decoder trying to reconstruct the input signal from latent representation. The difference here is that the encoder will get only small part of the input.
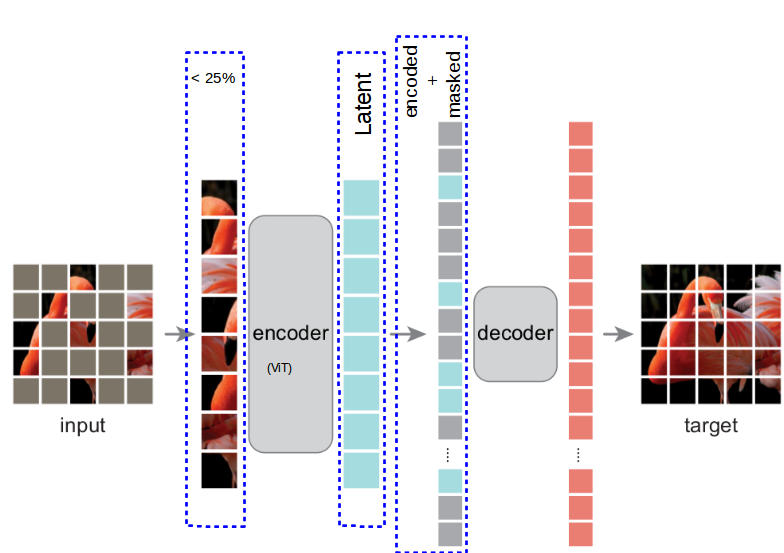 Figure 1a. MAE architecture.
Figure 1a. MAE architecture.
The input signal is an image divided into uniformly distributed and non-overlapping patches regularly created from image. Depending on the scenario only less than $25\%$ of the patches will be treated as encoder's input and mapped into latent representation. The rest of the patches, so called masked tokens will be directly forwarded to decoder input. Such a sparse input enables encoder to create an efficient mapping.
Encoder is a ViT with regular linear projection and positional embeddings followed by series of Transformer blocks, but due to only lest than quarter of visible patches causes it to use less compute and memory.
The input of the decoder becomes the latent representation of visible patches supplemented with the rest of the masked tokens all equipped with the positional embeddings. Decoder is is build out of series of Transformer blocks however, as it is used only during training it can be designed arbitrarily and independently of encoder. Authors reported to use by default decoder with $<10\%$ computation per token in comparison to encoder. This optimize time of the decoder needed during pre-training phase of learning the representation.
 Figure 2. Masking images validation examples with masking ratio 80% (39 of 196 patches encoded).
Figure 2. Masking images validation examples with masking ratio 80% (39 of 196 patches encoded).
Masked | Reconstruction | Original Image
The decoder (ViT) output is a vector of pixel values reconstruction predictions for each patch. Number of decoder output channels equals the number of patches in the image.
The mean sqiuared error (MSE) is the loss function calculated between the predicted and original image in the pixel space - however, only for masked patches (as in BERT). It is worth mentioning that the pixel performance advantage over BEiT is present when the pixels are normalized across each patch.
Processing steps🔗
- For every image a list of tokens with positional embeddings is created for every patch. The tokens are then randomly shuffled and the masked ratio is removed from the end of the list.
- For tokens remaining in the list encoder produces latent representation
- To the list containing latent representation we append the list of masked tokens, and based on the positional embeddings the order is restored in the list - unshuffle
- Decoder consumes the list as an input.
The only overhead are the shuffle and unshuffle operations, but those are fast.
Metaphors, or analogies to other architectures describing the behavior of the algorithm🔗
-
The natural reference for this kind of research is BERT and GPT that use the pre-training phase by deliberately hold out parts of the input sequences and aim to train the models to predict the missing values. however, BERT and GPT were developed for high semantic density modality of NLP.
-
The part of the MAE that learns to reconstruct the noised input signal can be referred to as a non-classical form of denoising autoencoders (DAE).
-
In terms of modern self-supervision learning counterparts of MAE they use contrastive learning, negative sampling, image (dis)similarity (SimCLR, MoCo, BYOL, DINO), and are strongly dependent on the tedious use of augmentation methods for the input images. MAE does not rely on those augmentations which are replaced by random masking.
Heuristics or rules of thumb🔗
Authors reported high masking ratio as the optimal for MAE:
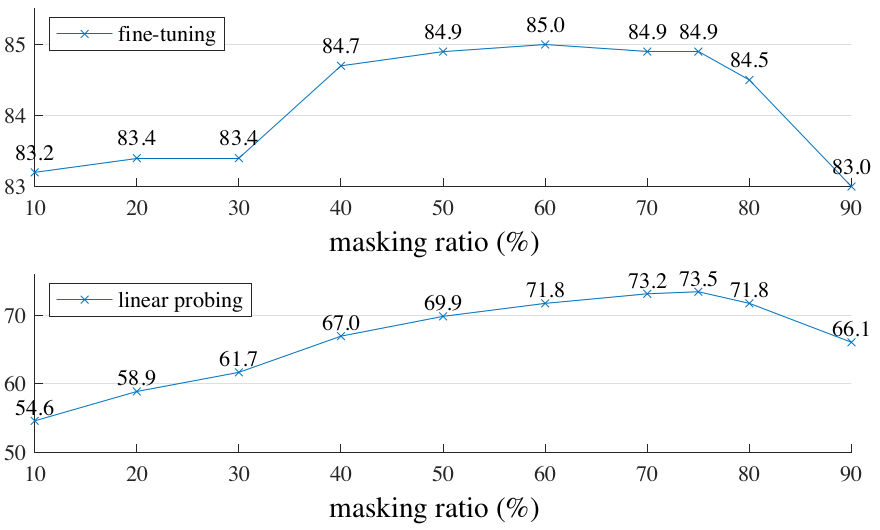 Figure 3. Masking ratio performance for fine-tunning vs linear probing.
Figure 3. Masking ratio performance for fine-tunning vs linear probing.
and present the adequate visualization:
 Figure 4. Masking ratio results.
Figure 4. Masking ratio results.
Probably an intuitive conclusion is that the longer we pre-train, the better accuracy we get2.
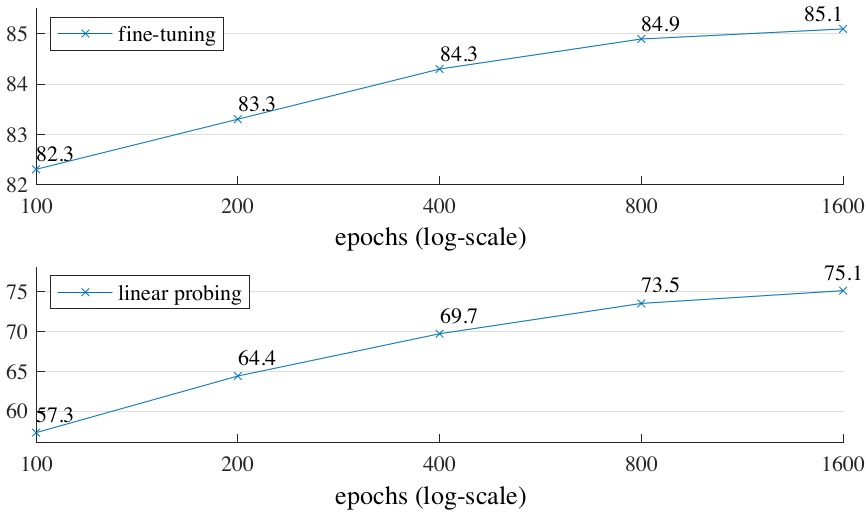 Figure 5. Longer training gives noticeable improvements.
Figure 5. Longer training gives noticeable improvements.
The simplification of decoder in MAE can get as far as a single Transformer block and would perform almost equally well if the encoder is later fine-tuned (84.8% - see Table 1.a). A single Transformer block is the minimal requirement to propagate information from visible tokens to mask tokens.
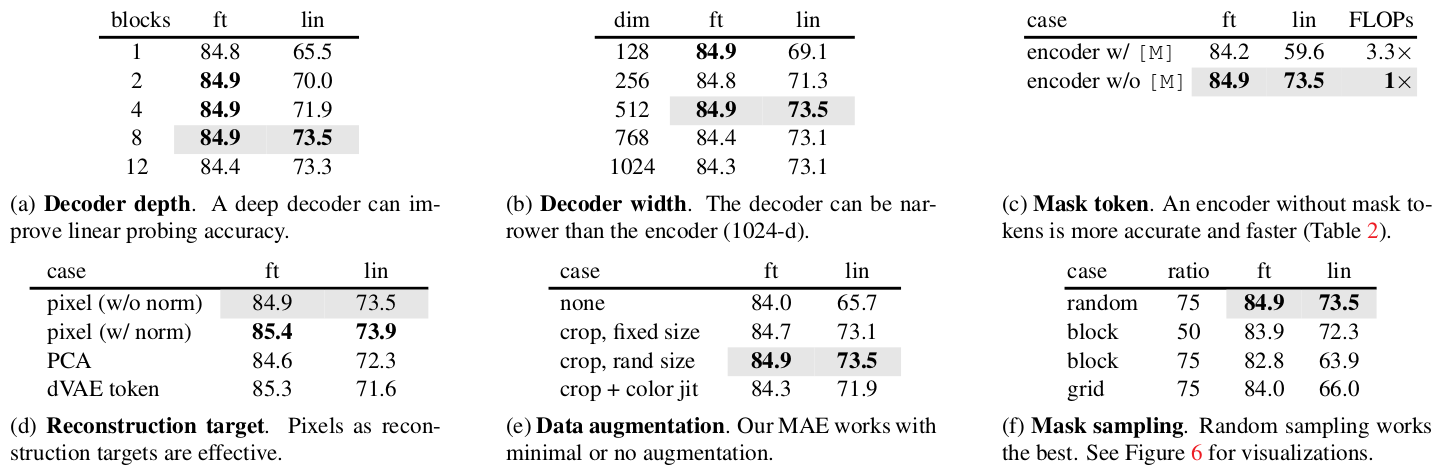 Table 1. MAE ablation experiments.
Table 1. MAE ablation experiments.
Comparing to BEiT, MAE is reported to be more accurate and being simpler and faster (3.5× per epoch; see Table 1.c).
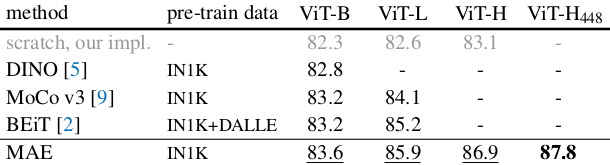
Table 2. MAE compared to remaining SSL solutions.
One last very interesting finding is study of partial fine-tuning - i.e fine-tune the last several layers while freezing the others. From the Figure 6. MAE representations seems to be less linearly separable, but better than MoCo v3 while at least one block is tuned. However, they are stronger non-linear features and perform well when a non-linear head is tuned. The conclusion could be here that linear separability is not the sole metric for evaluating representation quality.
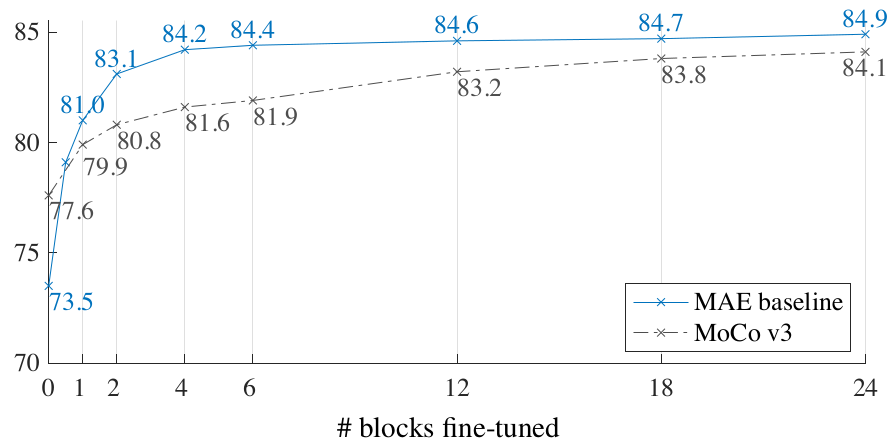
Figure 6. MAE partial fine-tuning vs MoCo.
Authors claim that thanks to the scaling benefits of MAE it can help to shift the general supervised paradigm for pre-training in computer vision to a more self-supervised trajectory.
The masking of semantically insignificant information from image, as well as pixel-oriented processing - which is lower semantic level than common recognition tasks - seems to work with MAE, and non semantic reconstruction is reported to be more suitable for sparse semantic information of image modality. It is backed by the fact that despite not using such semantic information in processing strategy of the algorithm it is still reconstructing visual concepts that actually represent semantic information in form of visual concepts.
Applications: classes of problem is the algorithm well suited🔗
Algorithm is particularly suited for preparing visual representation pre-training that later can be used for computer vision downstream tasks with use of fine tuning.
Common benchmark or example datasets used to demonstrate the algorithm🔗
MAE evaluation on three tasks show not only its superiority to pre-trained alternatives, but also significant advantage by scaling up models.
- Object detection & segmentation (COCO): Paper discusses results for transfer learning experiments with AP box and masked for ViT-base/Vit-large. MAE performs better than supervised pre-training in all configurations.
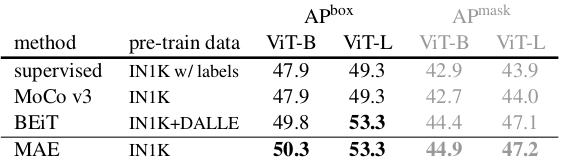
Table 3. MAE vs BEiT Object detection and segmentation.
The pixel-based MAE is sometimes at worst on par with the token-based BEiT, however MAE is much simpler and faster.
- Semantic segmentation: MAE outperforms the token-based BEiT and improves even more over the ViT-L transferring results for supervised pre-training.
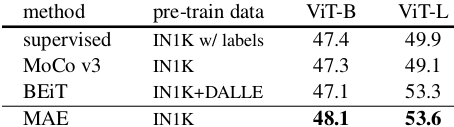
Table 4. MAE vs BEiT Semantic segmentation.
Next steps🔗
Future research could focus around performance study of:
- number of patches chosen in different mask sampling strategies (grid, uniform, crop-alike) at train time.
- dynamic / non fixed number of patches depending of training epoch
Useful resources for learning more about the algorithm:🔗
- "Masked Autoencoders Are Scalable Vision Learners" Kaiming He et al.- ArXiv Paper - 2021
- "Bootstrap your own latent: A new approach to self-supervised Learning"- Grill at al. ArXiv Paper - 2020
- "A Simple Framework for Contrastive Learning of Visual Representations" - Chen et al. ArXiv Paper - 2020
- "Momentum Contrast for Unsupervised Visual Representation Learning" Kaiming He et al.- ArXiv Paper 2019
Footnotes:🔗
- It is worth mentioning that because the first author and the project lead of this paper - Kamming He - is actually also the first author of the Deep Residual Learning for Image Recognition, as well as the Momentum Contrast for Unsupervised Visual Representation Learning ↩
- On the down sides it is worth mentioning that ViTs need to be trained a lot longer than ResNets - see How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers, and that in general long training is good in Knowledge distillation: A good teacher is patient and consistent ↩
Comments
comments powered by Disqus